
Ugh! I stopped stopping to update this page because I got the feedback that it's not a good idea! I might stop stopping to stop! So don't count on it!
I have stopped updating this page because it's too much work and I have been lazy with updating my resume and web pages lately! [Also aren't we passed the point of manually editing this stuff and AI should just take care of it without us asking? UGH!] But guess what? I have been busy with doing actual cool work instead! Checkout my twitter (or X or whatever!) for more updates!
Selected Works
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
M Deitke, C Clark, …, Kiana Ehsani, et. al. • Arxiv • 2024
Molmo and PixMo present open weights and open data to advance multimodal AI models, pushing the boundaries of state-of-the-art performance across various tasks.
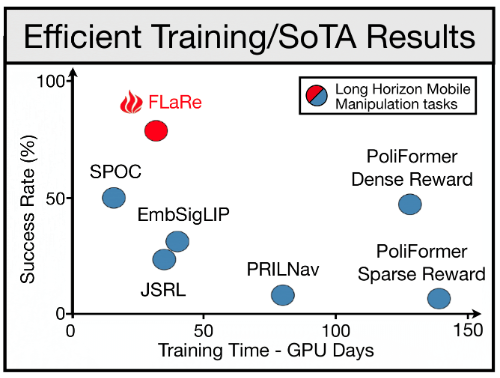
FLaRe: Achieving Masterful and Adaptive Robot Policies with Large-Scale Reinforcement Learning Fine-Tuning
J Hu, R Hendrix, A Farhadi, A Kembhavi, R Martin-Martin, P Stone, KH Zeng, Kiana Ehsani • Arxiv • 2024
FLaRe utilizes large-scale reinforcement learning fine-tuning to create adaptive and highly capable robot policies, achieving state-of-the-art results in both simulated and real-world environments.

Manipulate-Anything: Automating Real-World Robots using Vision-Language Models
Jiafei Duan*, Wentao Yuan*, Wilbert Pumacay, Yi Ru Wang, Kiana Ehsani, Dieter Fox, Ranjay Krishna • CoRL • 2024
(Paper) (Website) (Video) (Code)
Manipulate-Anything, is a scalable automated method for generating real-world robotic manipulation data without privileged state information or hand-designed skills, significantly outperforming existing methods and training more robust behavior cloning policies.
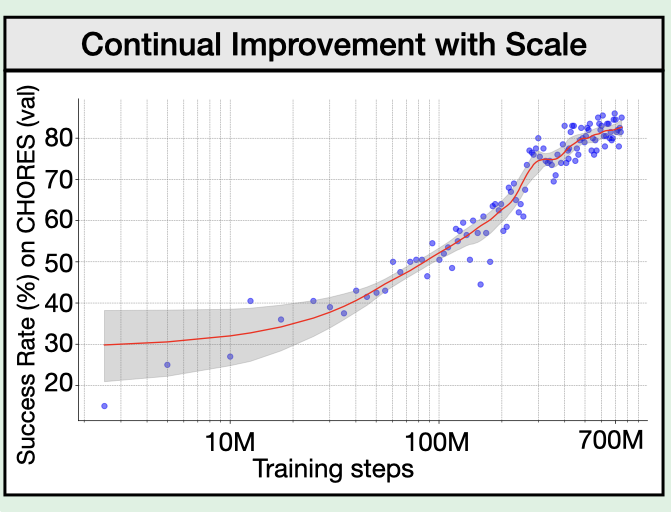
PoliFormer: On-Policy RL with Transformers Results in Masterful Navigators
Kuo-Hao Zeng, Zichen "Charles" Zhang, Kiana Ehsani, Rose Hendrix, Jordi Salvador, Alvaro Herrasti, Ross Girshick, Aniruddha Kembhavi, Luca Weihs • CoRL • 2024
Policy TransFormer (PoliFormer) is a transformer-based policy trained using RL at scale in simulation. PoliFormer achieves SoTA results across LoCoBot and Stretch RE-1, in both simulation and real-world.

Harmonic Mobile Manipulation
Ruihan Yang, Yejin Kim, Aniruddha Kembhavi, Xiaolong Wang, Kiana Ehsani • IROS • 2024
🎉 Best Paper Award
HarmonicMM is an end-to-end learning approach that combines navigation and manipulation, significantly improving success rates in complex tasks like door opening and table cleaning, with successful real-world transfer of agents trained in simulation.
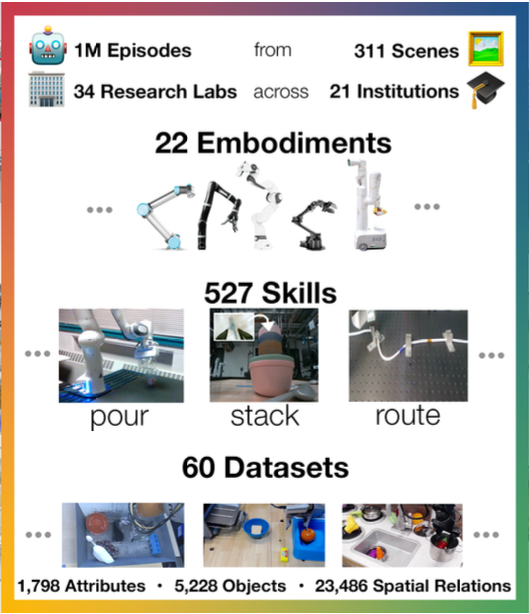
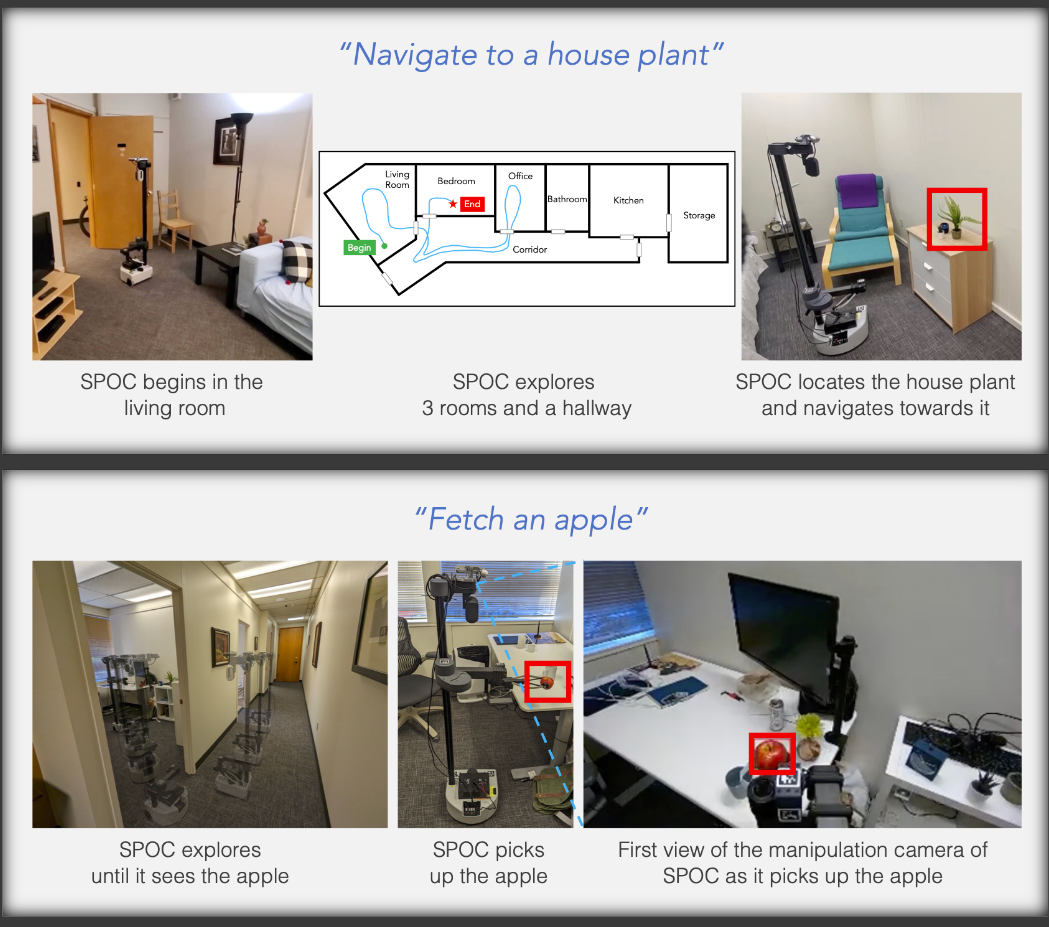
SPOC🖖: Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World
Kiana Ehsani*, Tanmay Gupta*, Rose Hendrix*, Jordi Salvador*, Luca Weihs*, Kuo-Hao Zeng*, Kunal Pratap Singh, Yejin Kim, Winson Han, Alvaro Herrasti, Ranjay Krishna, Dustin Schwenk, Eli VanderBilt, Aniruddha Kembhavi • CVPR • 2024
We train a supervised model to imitate shortest path trajectories collected from simulation and show that it generalizes to perform effective navigation and manipulation when deployed on real world agents.

Promptable Behaviors: Personalizing Multi-Objective Rewards from Human Preferences
Minyoung Hwang, Luca Weihs, Chanwoo Park, Kimin Lee, Ani Kembhavi, Kiana Ehsani • CVPR • 2024
We propose a novel framework that facilitates efficient personalization of robotic agents to diverse human preferences in complex environments.

Objaverse-XL: A Universe of 10M+ 3D Objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl Vondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt*, Ali Farhadi* • NeurIPS • 2023
We introduce Objaverse-XL, an open dataset of over 10 million 3D objects. With it, we train Zero123-XL, a foundation model for 3D, observing incredible 3D generalization abilities. With the Zero123-XL base model, we can then perform image-to-3D and text-to-3D.


Objaverse: A Universe of Annotated 3D Objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, Ali Farhadi • CVPR • 2023
Objaverse is a massive dataset of objects with 800K+ (and growing) 3D models with descriptive captions, tags, and animations. We demonstrate it's potential by training generative models, improving 2D instance segmentation, training open-vocabulary object navigation models, and creating a benchmark for testing the robustness of vision models.
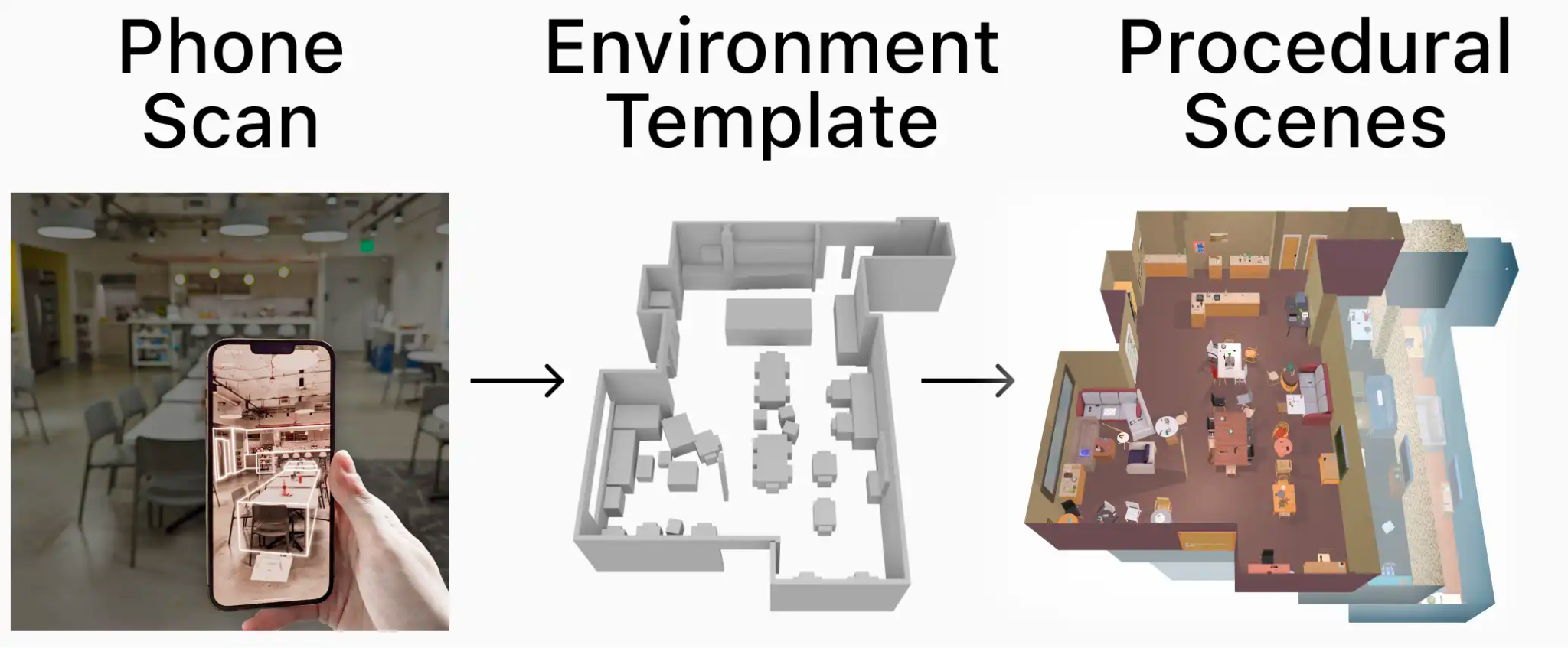
Phone2Proc: Bringing Robust Robots Into Our Chaotic World
Matt Deitke*, Rose Hendrix*, Luca Weihs, Ali Farhadi, Kiana Ehsani, Aniruddha Kembhavi • CVPR • 2023
From a 10-minute iPhone scan of any environment, we generated simulated training scenes that semantically match that environment. Training a robot to perform ObjectNav in these scenes dramatically improves sim-to-real performance from 35% to 71% and results in an agent that is remarkably robust to human movement, lighting variations, added clutter, and rearranged objects.

🏘️ ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, Roozbeh Mottaghi • NeurIPS • 2022
🎉 Outstanding Paper Award
We built a platform to procedurally generate realistic, interactive, simulated 3D environments to dramatically scale up the diversity and size of training data in Embodied AI. We find that it helps significantly with performance on many tasks.
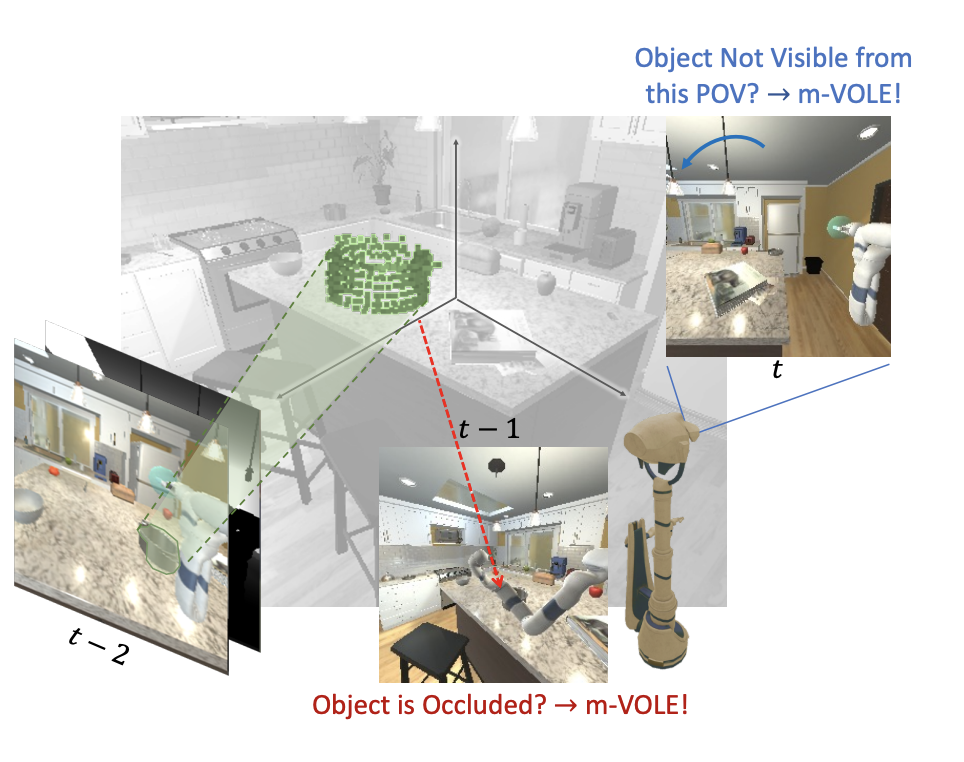
Object Manipulation via Visual Target Localization
Kiana Ehsani, Ali Farhadi, Aniruddha Kembhavi and Roozbeh Mottaghi • ECCV • 2022
Manipulation via Visual Object Location Estimation (m-VOLE) enhances Embodied AI agents' ability to manipulate objects by robustly estimating their 3D locations, even when not visible, significantly improving success rates in manipulation tasks and offering a more realistic approach to training agents for real-world object manipulation.
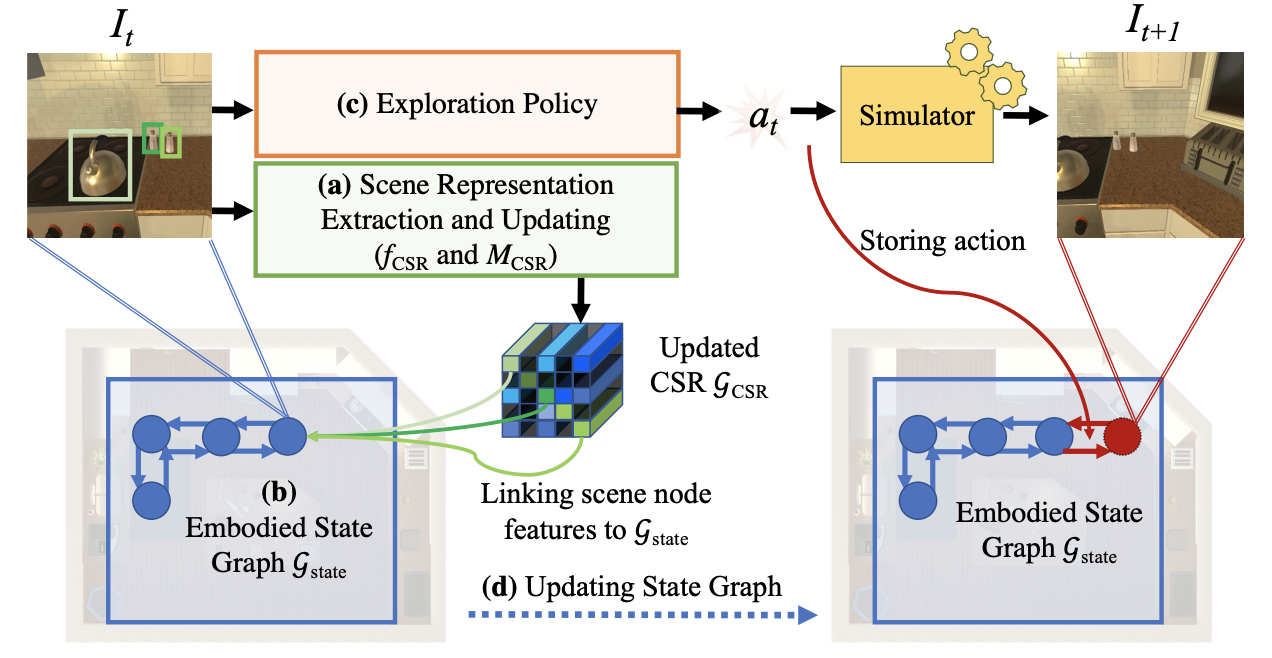
Continuous Scene Representations for Embodied AI
Samir Y Gadre, Kiana Ehsani, Shuran Song and Roozbeh Mottaghi • CVPR • 2022
Continuous Scene Representations (CSR) are proposed as a dynamic, graph-based method for modeling scenes by an embodied agent, using continuous embeddings to represent object relationships, enabling superior performance in visual room rearrangement tasks without specific training, and demonstrating relevance to real-world data.

Contrasting Contrastive Self-Supervised Representation Learning Pipelines
Klemen Kotar, Gabriel Ilharco, Ludwig Schmidt, Kiana Ehsani, and Roozbeh Mottaghi • ICCV • 2021
This paper analyzes the impact of training methods and datasets on the performance of self-supervised representation learning, focusing on contrastive approaches through an extensive study of over 700 experiments, examining their efficacy against supervised models and the influence of pre-training data on downstream tasks.
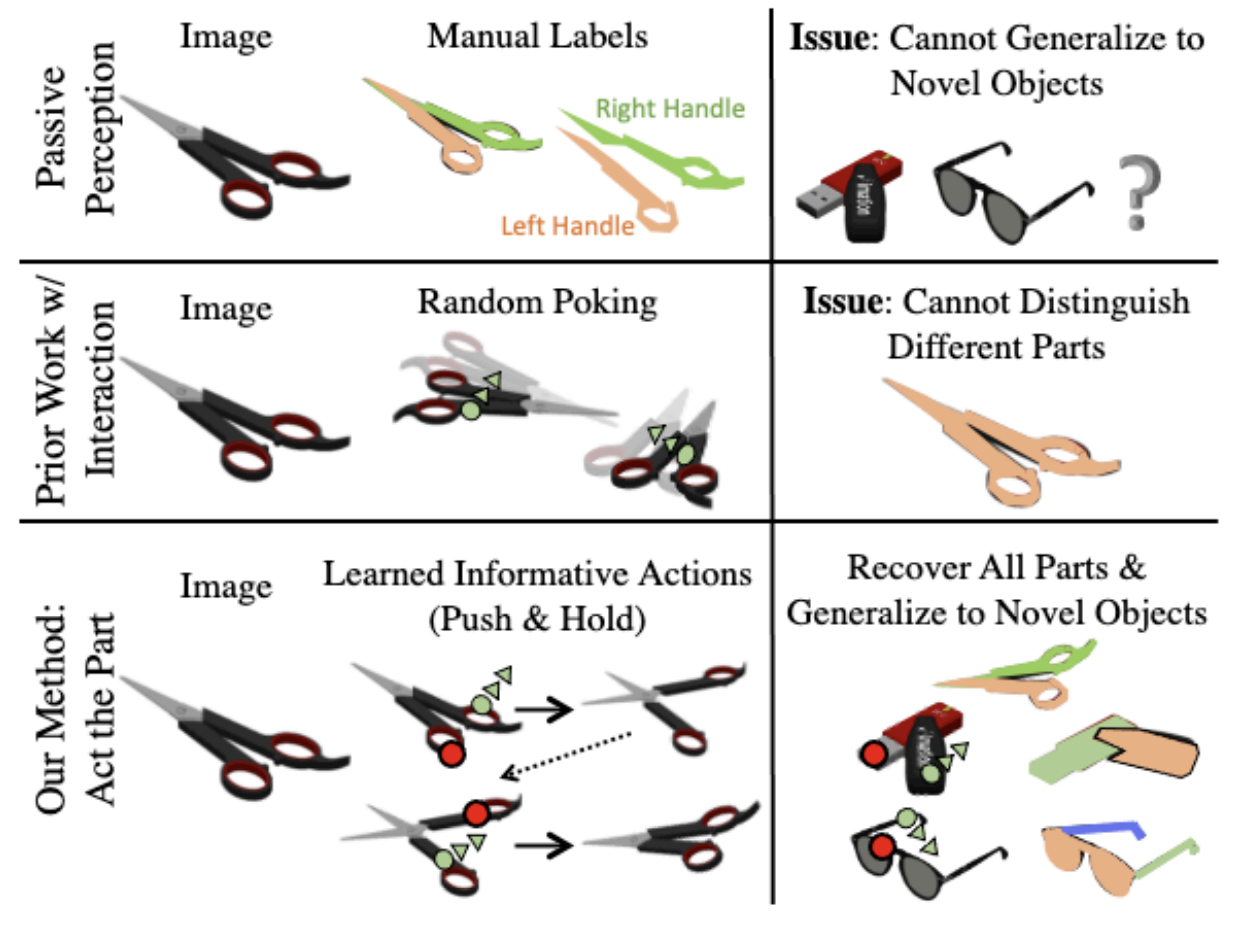
Act the Part: Learning Interaction Strategies for Articulated Object Part Discovery
Samir Y. Gadre, Kiana Ehsani, and Shuran Song • ICCV • 2021
Act the Part (AtP) is a method designed to interact with articulated objects to discover and segment their parts without semantic labels, demonstrating efficient part discovery strategies, generalization to unseen categories, and successful real-world transfer without fine-tuning.

ManipulaTHOR: A Framework for Visual Object Manipulation
Kiana Ehsani, Winson Han, Alvaro Herrasti, Eli VanderBilt, Luca Weihs, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi • CVPR • 2021
ManipulaTHOR is a framework designed for realistic object manipulation with a robotic arm in complex scenes, focusing on challenges like collision avoidance, grasping, planning, and generalization to new environments, equipped with a suite of sensory and motor functions for developing robust agents.

What Can You Learn from Your Muscles? Learning Visual Representation from Human Interactions
Kiana Ehsani, Daniel Gordon, Thomas Nguyen, Roozbeh Mottaghi, and Ali Farhadi • ICLR • 2021
This paper introduces a novel representation learning approach that leverages human interaction and attention cues, showing that this "muscly-supervised" method surpasses visual-only techniques in various tasks, including scene classification and action recognition.
Learning Generalizable Visual Representations via Interactive Gameplay
Luca Weihs, Aniruddha Kembhavi, Kiana Ehsani, Sarah M Pratt, Winson Han, Alvaro Herrasti, Eric Kolve, Dustin Schwenk, and 2 more... • ICLR • 2021
This research shows that embodied gameplay, essential for neural flexibility in both humans and animals, can similarly impact artificial agents, whose learning and vision development are enhanced through interactive play, offering a new model for experiential representation learning.
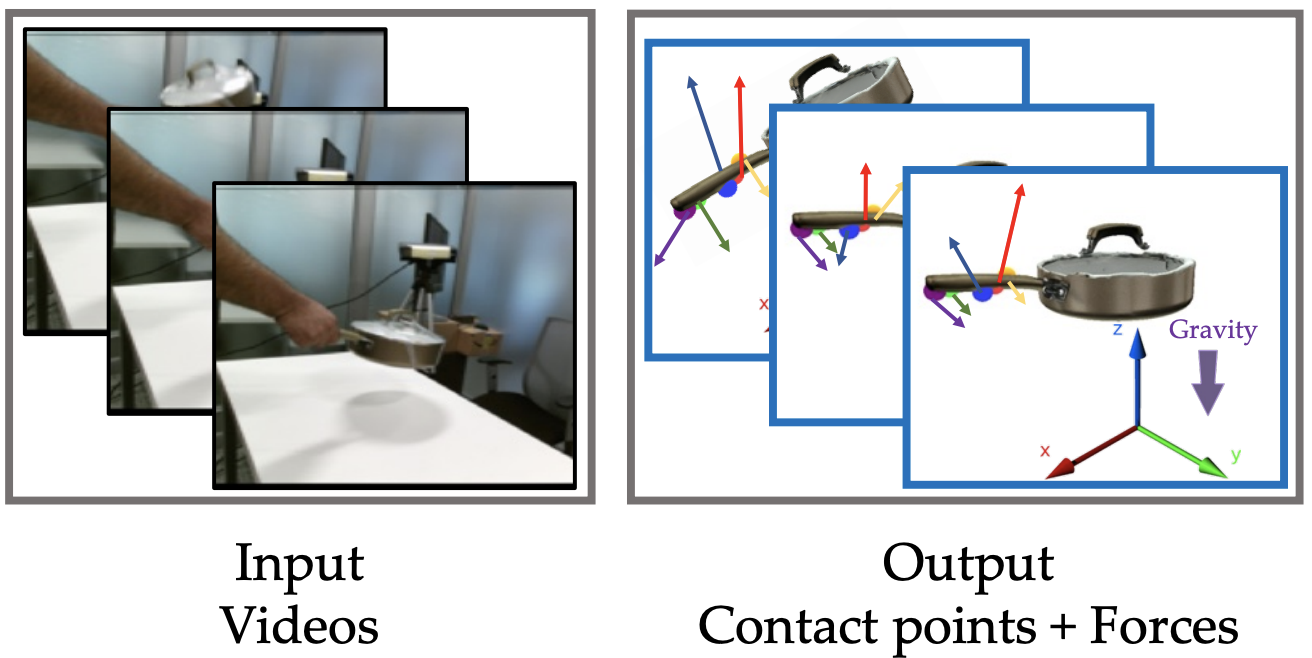
Use the Force, Luke! Learning to Predict Physical Forces by Simulating Effects
Kiana Ehsani, Shubham Tulsiani, Saurabh Gupta, Ali Farhadi, and Abhinav Gupta • CVPR • 2020
This paper advances the understanding of human-object interactions by inferring contact points and physical forces from videos, using a physics simulator for supervision to ensure predicted effects match those observed in the video.
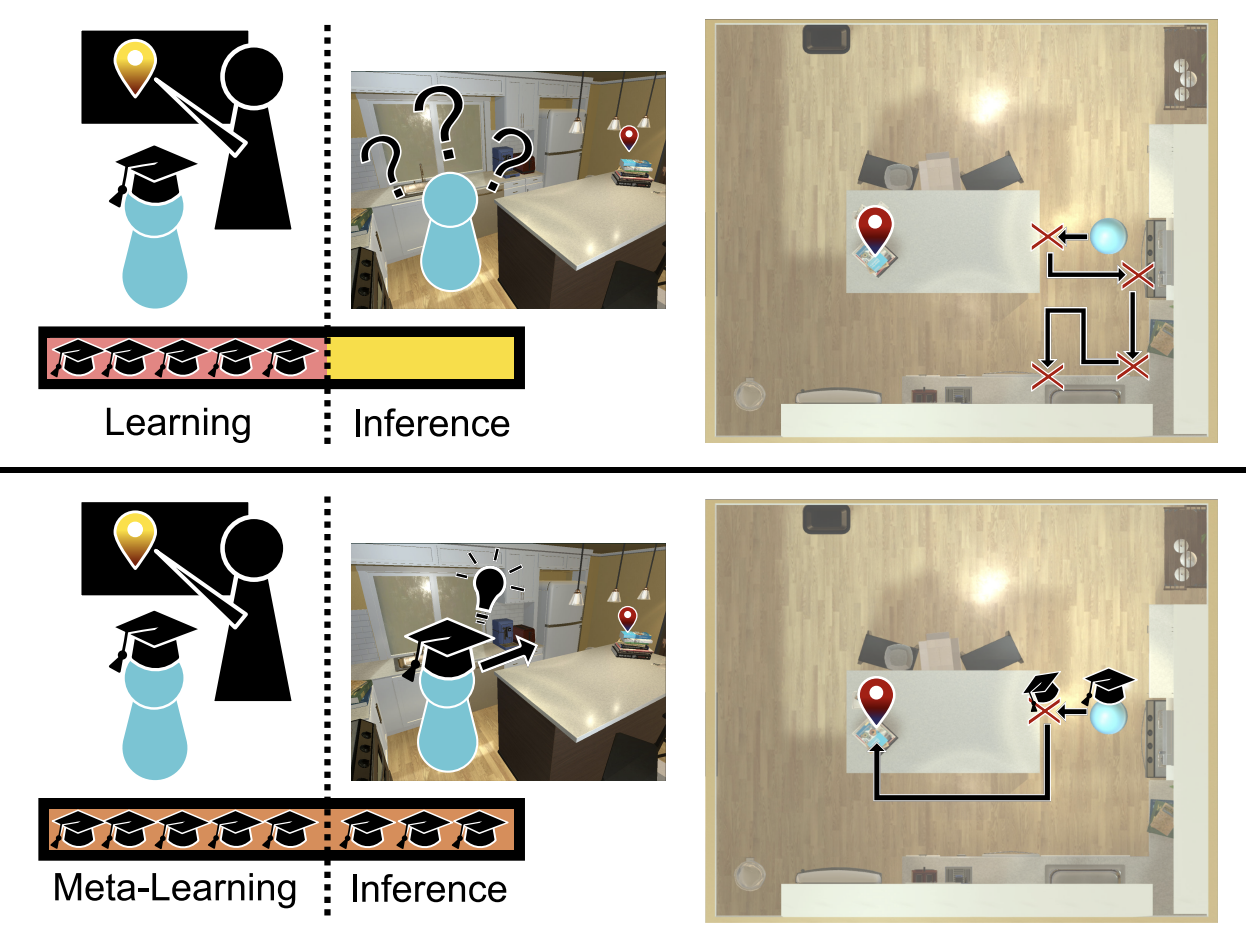
Learning to Learn How to Learn: Self-Adaptive Visual Navigation using Meta-Learning
Mitchell Wortsman, Kiana Ehsani, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi • CVPR • 2019
This paper introduces SAVN, a self-adaptive visual navigation method that uses meta-reinforcement learning to enable an agent to adapt and learn in new environments without explicit supervision, showing significant improvements in navigation success and efficiency.

Who Let The Dogs Out? Modeling Dog Behavior From Visual Data
Kiana Ehsani, Hessam Bagherinezhad, Joe Redmon, Roozbeh Mottaghi, and Ali Farhadi • CVPR • 2018
DECADE is a dataset that captures the world from a dog's perspective, enabling the modeling of a visually intelligent agent that can predict and plan movements, thereby offering unique insights and improvements in visual intelligence tasks.
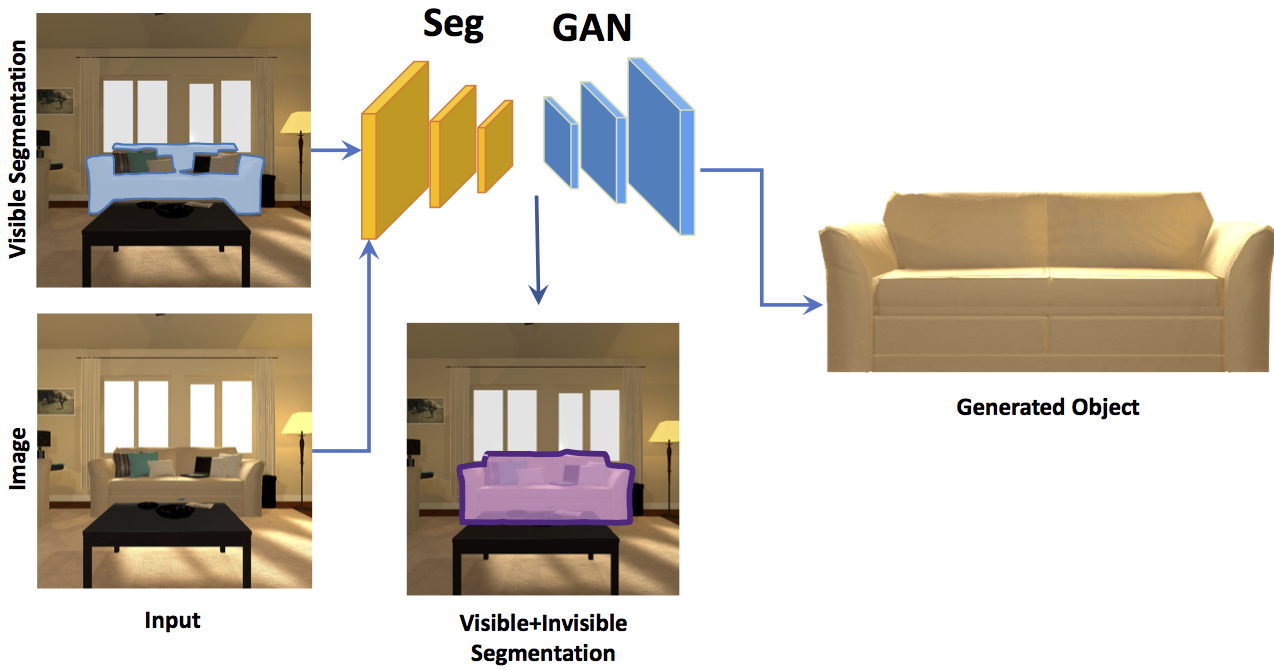
SeGAN: Segmenting and Generating the Invisible
Kiana Ehsani, Roozbeh Mottaghi, and Ali Farhadi • CVPR • 2018
(Paper) (Code) (Website) (Data)
SeGAN is designed to generate and segment occluded parts of objects and infer depth layering, even when trained on synthetic images, it can reliably process natural images by understanding occluder-occludee relationships.